创建地形模型
在操作或编辑点云(根据需要)之后,下一步是创建地形模型。可以使用整个点云,也可以使用点云演示来限制对某些分类的导入,或者可以将围栅放置在相关区域中。围栅应在启动该工具之前放置。
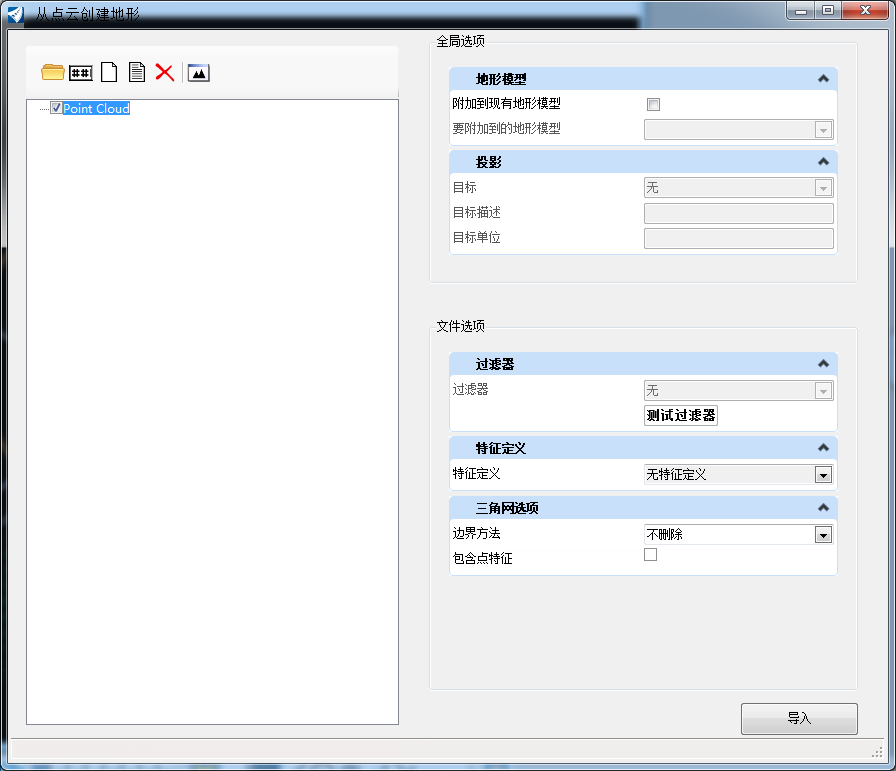
该对话框的左上角支持两个工具:
 重命名地形模型
重命名地形模型  移除地形模型
移除地形模型 该对话框的右窗格中支持以下选项:
-
地形模型 - 此类选项指示激活 *.dgn 文件中是否已存在地形模型以及如何与要导入的数据组合。
-
过滤器 - 对于大型数据集,过滤可能是一个十分有用的选项。
-
特征定义 - 用于导入地形的特征定义。如果未选择任何选项,则使用激活线符绘制地形模型。
-
地理坐标系 (GCS) - 如果软件可以确定要导入的文件的地理坐标系,则填充字段。如果设置为未知,则该软件将使用 MicroStation 设计单位。如果生成的地形模型需要位于不同的 GCS 中,则使用本部分。
按平铺 TIN 过滤
此工具支持两种过滤算法。一种基于平铺,另一种基于其他 TIN 或三角网。从经验研究来看,平铺算法更快,通常可以使文件大小减少 30% 到 50%。TIN 算法通常可以减少 70% 到 90%。
平铺算法是一种递归分治算法,它将 LIDAR 数据集划分为分块。为每个分块计算最佳拟合平面,如果 LIDAR 点落在用户设置的平面 Z 公差范围内,则将其移除。
如果 LIDAR 点落在三角形平面的用户设置 Z 公差范围内,则 TIN 算法会对其进行过滤。TIN 算法首先将 LIDAR 点平铺到具有最多 200 万个点的分块中,然后重复对每个分块进行三角形化以过滤点。此算法在具有 1 GB 内存的 1.67 GHz 计算机上运行,通常需要大约 12 分钟来过滤 3000 万个 LIDAR 点。
|
设置 |
描述 |
|
文件选项 |
平铺或 TIN 过滤器 |
|
Z 公差 |
Z 公差对于两种算法都是通用的,基本上是在过滤过程中允许曲面在 Z 坐标中移动的变化。通常在第一次调用过滤函数时,对于英制数据集,Z 公差应设置为 0.5 到 1.0,对于公制数据集,应设置为 0.25 到 0.5。根据效果和所需结果,Z 公差可以上下变化。 |
|
最小平铺点(平铺) |
如果平铺的点数少于此数,则平铺不会细分。通常,此数量设置为 5。 |
|
最大平铺分界线(平铺) |
是指允许的递归级别,且是指初始平铺集可以细分的次数。通常,此数量设置为 5。 |
|
起始平铺长度(平铺) |
在递归到最小平铺点之前,LIDAR 数据集最初被分为该大小的分块。此参数的设置需要了解 LIDAR 点之间的距离,这需要检查 MicroStation 中的 LIDAR 点进行确定。通常将其设置为 LIDAR 点之间距离的 10 倍。 |
|
粗滤器 (TIN) |
过滤更多的点,且脊和山谷较模糊。 |
|
精滤器 (TIN) |
过滤更少的点,且脊和山谷较清晰。 |
|
重新插入点 (TIN) |
如果地形上的迭代过滤移除公差范围内的点,则重新插入点会再次添加点。例如,此过程可以移除山顶的点,第二次迭代可以移除高点周围的点,使得该点超出细化公差。迭代过程最多可发生五次。 |
工作流